




Resolvi criar este post com o objetivo de destrinchar em pequenas partes o macro-conceito de "escalar a aplicação".
Hoje em dia, ouvimos muito falar sobre criação de aplicações estáveis e escaláveis, que sejam tolerante à falhas, que façam balanceamento de carga, etc. Para quem já se perdeu na parte de "aplicações estáveis..." o resto já começa a não fazer nenhum sentido.
Então, vamos lá começar a destrinchar essa sopa de palavras e tentar deixar os conceitos mais claros e acessíveis para todas as pessoas.
Arquitetura Tradicional
Antes de começarmos a falar de uma arquitetura escalável, vamos entender como que funciona uma arquitetura tradicional, que não leva em conta variáveis de escala.
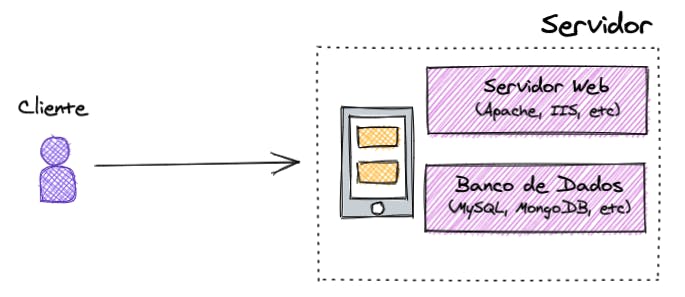
Na imagem, temos o clássico exemplo de arquitetura cliente-servidor. Onde tudo fica hospedado em um servidor, com uma estrutura básica contendo um servidor web (como o Apache, IIS, etc) e um banco de dados (como o MySQL, MongoDB, etc).
Esse servidor fica aguardando alguma requisição vinda de algum cliente para processar e devolver a este mesmo cliente o resultado esperado.
Arquitetura Escalável
A arquitetura escalável é focada em resolver problemas de sobrecarga de acessos e, a partir daí, gerenciar melhor os recursos para evitar um custo altíssimo com toda essa estrutura que podemos configurar.
Quanto mais a sua aplicação ganha usuários, maior será a quantidade de requisições que ela irá receber simultaneamente. E quanto maior for esse número, maior terá que ser sua preocupação com a infraestrutura em termos de dimensionamento (escala).
E quando falamos de dimensionamento, temos 2 tipos conhecidos: vertical e horizontal.
Dimensionamento Vertical (Vertical Scaling)
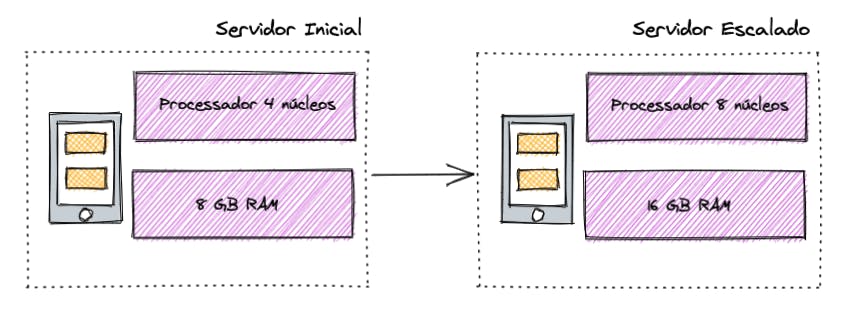
Em linhas gerais, quando falamos em "escalar verticalmente", significa que vamos aumentar os recursos do servidor para aguentar mais requisições. Mas é praticamente a mesma arquitetura que vimos no modelo tradicional.
Está estourando a memória? Aumenta a memória!
Está travando os processos? Aumenta os núcleos do processador!
Não preciso nem dizer que esse tipo de solução não vai resolver todos os nossos problemas, né? Já pensou se seu servidor já está com 32 núcleos e 128 GB de memória e ainda continua estourando memória e travando os processos? Se a gente continuar escalando verticalmente, a conta vai sair muito cara e só resolverá temporariamente até precisar escalar novamente, e por aí vai!
Além disso, o dimensionamento vertical nos traz outro problema: não é tolerante à falhas! Se o servidor cair, a aplicação irá fora do ar até que alguém resolva o problema.
Com esse problemas, vamos ao outro tipo de dimensionamento: o horizontal.
Dimensionamento Horizontal (Horizontal Scaling)
Os problemas citados anteriormente podem ser resolvidos agora. Afinal, como poderemos aceitar milhares/milhões de requsições sem afetar nossa infra?
Resposta curta: instâncias!
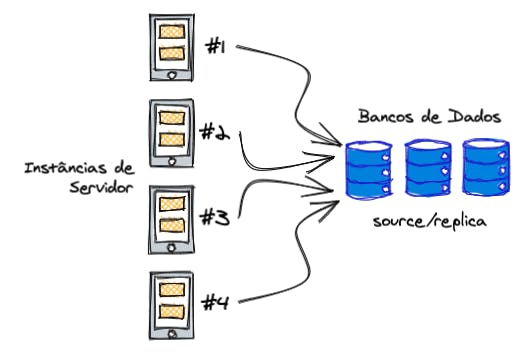
Tanto para o servidor, como para o banco de dados, podemos criar instâncias que irão receber o tráfego de acordo com a demanda.
No banco de dados, quando temos excesso de tráfego corremos o risco de derrubar o banco e ficar com a aplicação dando erro de conexão. Afinal, o banco não está mais lá, né?
Para isso, usamos a estratégia do source/replica (termo usado pela MySQL para substituir o obsoleto termo master/slave. Se você quer entender melhor essa mudança, pode conferir nessa página) do Wikipedia).
Essa estratégia consiste, basicamente, em replicar o banco de dados e quando o original (source) cair, promovemos a cópia (replica) para ser utilizada.
No servidor, quando começamos a ter os problemas de memória e quedas que mencionei anteriormente, ao invés de aumentar os recursos, criamos uma nova "cópia". Sendo assim, conforme o tráfego vai aumentando, as novas requisições vão sendo direcionadas para as outras instâncias.
Podemos fazer esse direcionamento de duas formas: utilizando a estratégia round robin onde cada nova requisição vai sendo direcionada para uma nova instância, e quando chegar na última volta para a primeira e assim sucessivamente. Ou podemos criar filtros no serviço de cloud utilizado para só direcionar para a próxima instância quando a capacidade estiver acima de 80% por exemplo.
Mas quem é o responsável por direcionar as requisições para as instâncias? O famoso balanceador de carga!
Balanceador de Carga (Load Balancer)
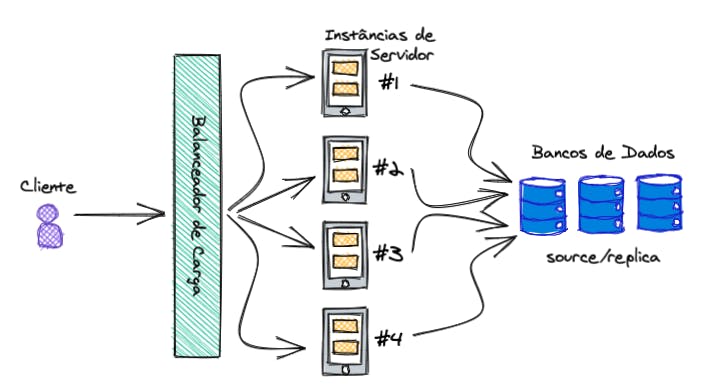
O balanceador é quem direciona as requisições para as instâncias de acordo com as regras definidas (round robin ou de acordo com a sobrecarga). Ele funciona como uma camada intermediária entre o cliente e o servidor. E ele usa os IP's das instâcias para fazer esse processo de roteamento.
Usando o balanceador de carga nós podemos ter o mesmo problema de não ser tolerante à falhas, e caso ele caia, nossa aplicação não conseguirá ser acessada, mesmo que os servidores e o banco de dados estejam funcionando perfeitamente. Em casos como esse, podemos ter um balanceador como backup.
Bom, os problemas de sobrecarga de requisições e tolerância à falhas foram resolvidos até aqui. Mas, como essas instâncias são criadas?
Uma estratégia é criar alertas. Posso criar um que, toda vez que a minha instância estiver usando mais de 80%, recebo uma notificação no meu celular. Aí vou lá e, manualmente, crio mais uma instância.
Resolve? Sim! Mas aí temos mais dois problemas: dependência da intervenção humana, e desperdício de recursos.
Intervenção humana: nem sempre a pessoa responsável pode estar disponível.
Desperdício de recursos: você vai lá e cria uma nova instância por causa da sobrecarga de requisições, mas e quando o tráfego baixar? Você vai ficar com duas instâncias, sendo que naquele momento bastava apenas uma. E isso custa muito dinheiro! :sweat_smile:
A solução aqui é o dimensionamento automatizado.
Dimensionamento Automatizado (Auto Scaling)
O nome é bem auto-explicativo. Podemos criar alguns filtros para provisionar e destruir as instâncias de acordo com a necessidade.
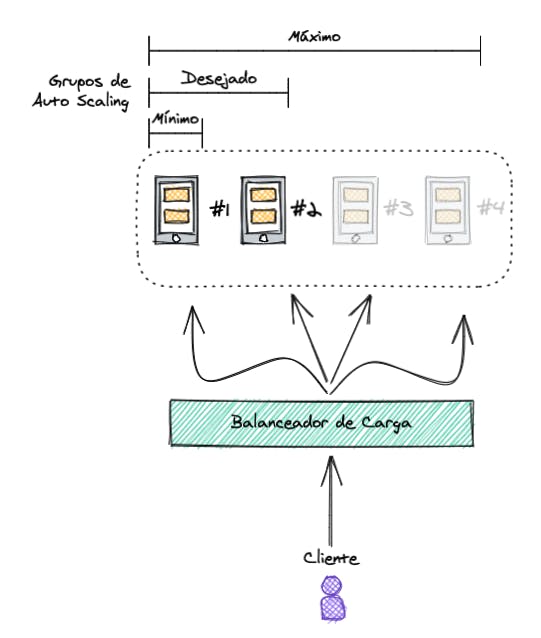
Na imagem podemos ver que existem grupos de auto scaling. Esses grupos devem conter um nome e uma capacidade mínima e máxima de instâncias que devem ser provisionadas. Você também pode especificar a capacidade desejada, que é o número de instâncias que o grupo deve ter por padrão.
Se você não especificar uma capacidade desejada, a capacidade mínima será o padrão.
Bom, um problema a menos agora que temos tudo automatizado.
Quando uma pessoa usuária acessa nossa aplicação ela é direcionada para a instância X. Nessa instância, ela se autentica e acessa a área para usuários autenticados. Quando clicar para ir à outra página, esse pessoa recebe o erro que essa é uma área para pessoas autenticadas, e direciona para o login.
Ué? O que aconteceu aqui? Ela não acabou de se autenticar? Por que está pedindo para se autenticar novamente?
Quando trabalhamos com mais de uma instância temos o problema de perda de sessão entre uma instância e outra. Porque sessões são armazenadas na própria instância e não tem como compartilhá-las entre instâncias.
A pessoa do exemplo acima, se logou na instância X. Quando ela clicou para ir à outra página, ela foi direcionada para a instância Y, mas a sessão de autenticação dela estava apenas na instância X.
E aí? Como resolver isso?
A solução para esse problema tem nome: camada de cache.
Camada de Cache (Cache Layer)
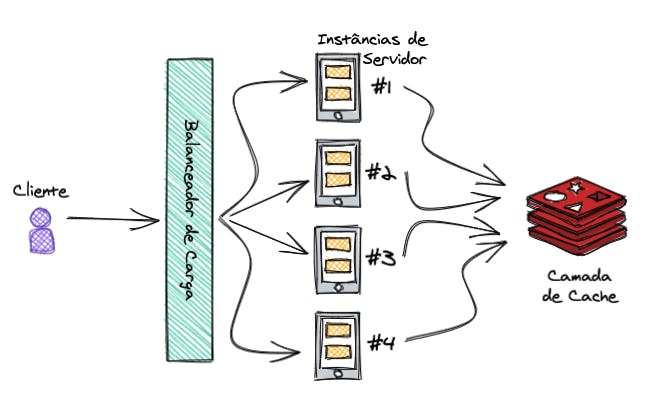
A camada de cache é responsável por armazenar as sessões e compartilhá-las entre as instâncias, evitando o problema que vimos acima.
Existem algumas ferramentas que fazem esse papel. Na imagem acima eu usei o logo do Redis que é uma das mais mais conhecidas (na realidade o Redis é um banco de dados do tipo key-value que armazena os dados na memória RAM do servidor, e que acaba sendo usado como ferramenta de cache por conta dessa principal característica).
Além de armazenar e compartilhar sessões, a camada de cache também ajuda bastante em outro problema muito recorrente quando estamos escalando a aplicação: fazer consultas no banco de dados custa dinheiro, e se você ficar fazendo consultas constantes que poderiam ser evitadas, sua conta no final do mês vai sair bem carinha! :scream:
Então, na camada de cache, podemos armazenar informações que não irão se alterar com muita frequência. Por exemplo, podemos armazenar os artigos recomendados para aquela pessoa de acordo com os que ela leu. Se em todas as páginas que essa pessoa visitar fossemos fazer uma consulta no banco... já sabe né? :money_with_wings:
Então, podemos criar um script para quando essa pessoa acessar nossa aplicação pela primeira vez no dia, vamos buscar no banco (para pegar dados atualizados), senão, vamos buscar na camada de cache.
Bom, acredito que já tenha dado para pegar a linha de raciocínio, certo?
Espero que você tenha gostado, e em breve trago novos conteúdos.